
بالابردن کارآیی Entity Framework
امروزه اهمیت استفاده از Entity Framework بر هیچ کسی پوشیده نیست؛ اما در صورتی که به مفاهیم ابتدایی آن آشنایی نداشته باشید ممکن است در دام هایی بیفتید که استفاده از آن کم رنگ شود. در زیر به توصیههایی جهت بالابردن کارآیی برنامههای مبتنی بر EF اشاره خواهیم کرد.
-
تنها دریافت رکوردهای مورد نیاز
تنها دریافت رکوردهای مورد نیاز
EF راهی برای کار با اشیاء POCO، بدون آگاهی از مقادیرشان میباشد. اما هنگام فرآیند دریافت و یا به روزرسانی مقادیر این اشیاء از بانک اطلاعاتی، رفت و برگشت هایی انجام میشود که اطلاع از آنها بسیار حیاتی و ضروری است. به این فرآیند materiallization میگویند.
string city = "New York";
List<School> schools = db.Schools.ToList();
List<School> newYorkSchools = schools.Where(s => s.City == city).ToList();در کد بالا ابتدا کلیه ردیفهای جدول از دیتابیس به حافظه منتقل میشود و سپس برروی آنها کوئری مورد نظر اعمال میگردد که بشدت میتواند برای یک برنامه – خصوصا برنامه وب – بهدلیل دریافت کلیهی ردیفهای جدول بسیار مخرب باشد. کوئری فوق را میتوان به صورت زیر اصلاح کرد:
List<School> newYorkSchools = db.Schools.Where(s => s.City == city).ToList();
یا
IQueryable<School> schools = db.Schools;
List<School> newYorkSchools = schools.Where(s => s.City == city).ToList();
-
حداقل رفت و برگشت به دیتابیس
حداقل رفت و برگشت به دیتابیس
کد زیر را در نظر بگیرید:
string city = "New York";
List<School> schools = db.Schools.Where(s => s.City == city).ToList();
var sb = new StringBuilder();
foreach(var school in schools)
{
sb.Append(school.Name);
sb.Append(": ");
sb.Append(school.Pupils.Count);
sb.Append(Environment.NewLine);
}هدف تکه کد بالا این است که تعداد دانش آموزان مدرسههای واقع در شهر New York را بدست آورد.
توجه داشته باشید:
- یک مدرسه میتواند چندین دانش آموز داشته باشد (وجود رابطه یک به چند)
- LazyLoading فعال است
- تعداد مدرسههای شهر نیویورک 200 عدد میباشد
اگر کوئری بالا را بهوسیلهی یک پروفایلر بررسی نمایید، متوجه خواهید شد 1 + 200 رفت و برگشت به دیتابیس صورت گرفته است که به “N+1 select problem” معروف است. 1 مرتبه جهت دریافت لیست مدرسههای شهر نیویورک و 200 مرتبه جهت دریافت تعداد دانش آموزان هر مدرسه.
بدلیل فعال بودن Lazy Loading، زمانیکه موجودیتی فراخوانی میشود، سایر موجودیتهای وابسته به آن، زمانی از دیتابیس فراخوانی خواهند شد که به آنها دسترسی پیدا کنید. در حلقهی foreach هم به ازای هر مدرسه (200 مدرسه) شهر نیویورک یک رفت و برگشت انجام میشود.
اما راه حل در این مورد خاص استفاده از Eager Loading است. خط دوم کد را بصورت زیر تغییر دهید:
List<School> schools = db.Schools
.Where(s => s.City == city)
.Include(x => x.Pupils)
.ToList();حال با یک رفت و برگشت، همراه هر مدرسه اطلاعات مربوط به دانش آموزان وابستهی آن نیز در دسترس خواهد بود.
-
تنها استفاده از ستونهای مورد نیاز
تنها استفاده از ستونهای مورد نیاز
فرض کنید قصد دارید نام و نام خانوادگی دانش آموزان یک مدرسه را بدست آورید.
int schoolId = 1;
List<Pupil> pupils = db.Pupils
.Where(p => p.SchoolId == schoolId)
.ToList();
foreach(var pupil in pupils)
{
textBox_Output.Text += pupil.FirstName + " " + pupil.LastName;
textBox_Output.Text += Environment.NewLine;
}کد بالا تمام ستونهای یک جدول را همراه با ستونهای نام و نام خانوادگی جدول مربوطه را از دیتابیس فراخوانی میکند که باعث بروز 2 مشکل زیر میگردد:
- انتقال اطلاعات بلا استفاده که ممکن است باعث کاهش کارآیی Sql Server I/O و شبکه و اشغال حافظهی کلاینت گردد.
- کاهش کارآیی ایندکس گذاری. فرض کنید برروی جدول دانش
آموزان ایندکسی شامل 2 ستون نام و نام خانوادگی تعریف کردهاید. با انتخاب
تمام ستونهای جدول توسط خط دوم (select * from…) به کارآیی ایندکس گذاری
برروی این جدول آسیب زدهاید. توضیح بیشتر در اینجا مطرح شده است.
اما راه حل:
var pupils = db.Pupils
.Where(p => p.SchoolId == schoolId)
.Select(x => new { x.FirstName, x.LastName })
.ToList();
-
عدم تطابق نوع ستون با نوع خصیصه مدل
عدم تطابق نوع ستون با نوع خصیصه مدل
فرض کنید نوع ستون جدول دانش آموزان (VARCHAR(20 است و خصیصه کدپستی مدل دانش آموز مانند زیر تعریف شده است:
public string PostalZipCode { get; set; }انتخاب نوع داده و تطابق نوع داده مدل با ستون جدول دارای اهمیت زیادی است و در صورت عدم رعایت، باعث کاهش کارآیی شدید میگردد. در کد زیر قصد دارید لیست نام و نام خانوادگی دانش آموزانی را که کدپستی آنها 90210 میباشد، بدست بیاورید.
string zipCode = "90210";
var pupils = db.Pupils
.Where(p => p.PostalZipCode == zipCode)
.Select(x => new {x.FirstName, x.LastName})
.ToList();کوئری بالا منجر به تولید SQL زیر میگردد: (نوع پارامتر ارسالی NVARCHAR است در حالی که ستون از نوع VARCHAR)
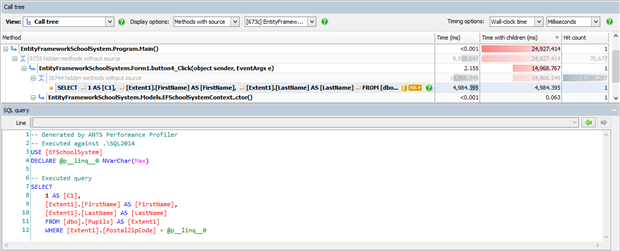
هنگامیکه کوئری بالا را اجرا نمایید، زمان زیادی جهت اجرای آن صرف خواهد شد. در صورتی که از یک پروفایلر استفاده نمایید، میتوانید عملیات پرهزینه را شناسایی نمایید و اقدام به کاهش هزینهها کنید.
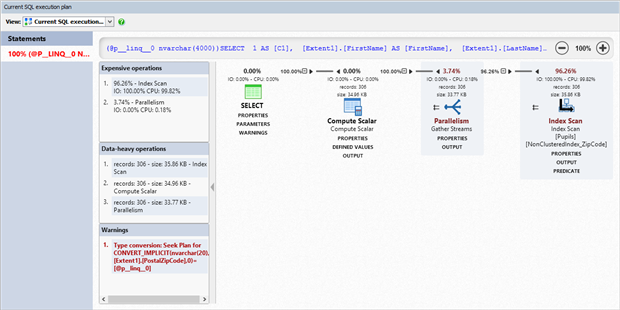
همانطور که در شکل بالا مشخص است عملیات index scan از سایر عملیاتها پرهزینهتر است. حال به بررسی علت بهوجود آمدن این عملیات پرهزینه خواهیم پرداخت.
Index Scan زمانی رخ میدهد که اس کیو ال سرور مجبور است هر صفحهی از ایندکس را بخواند و شرایط را (کدپستی برابر 90210) اعمال نماید و نتیجه را برگرداند. Index Scan بسیار هزینه بر است، چون اس کیو ال سرور، کل ایندکس را بررسی مینماید. نقطهی مقابل و بهینهی آن، Index Seek است که اس کیو ال سرور به صفحهی مورد نظر ایندکسی که به شرایط نزدیکتر است، منتقل میگردد.
خب چرا اس کیو ال سرور Index Scan را بجای Index Seek انتخاب کرده است؟!
اشکالی در قسمت سمت چپ شکل بالا که به رنگ قرمز نمایش داده شده است، وجود دارد:
Type conversion: Seek Plan for CONVERT_IMPLICIT(nvarchar(20), [Extent1].[PostalZipCode],0)=[@p__linq__0][Extent1].[PostalZipCode] بصورت غیر صریح به (NVARCHAR(20 تبدیل شده است. اما چرا؟
پارامتر کوئری تولید شدهی توسط EF از نوع NVARCHAR است و تبدیل نوع NVARCHAR پارامتر کدپستی، که محدودهی اطلاعات بیشتری (Unicode Strings) را نسبت به نوع VARCHAR ستون دارد، بهدلیل از دست رفتن اطلاعات امکان پذیر نیست. بههمین جهت برای مقایسهی پارامتر کدپستی با ستون VARCHAR ، اس کیو ال سرور باید هر ردیف ایندکس را از VARCHAR به NVARCHAR تبدیل نماید که منجر به Index Scan میشود. اما راه حل بسیار ساده این است که فقط نوع خصیصه را با ستون جدول یکسان کنید.
[Column(TypeName = "varchar")]
public string PostalZipCode { get; set; } مطلب قبلی
مطلب قبلی مطلب بعدی
مطلب بعدی