
جدول تحلیلی (pivot) در SQL Server
فرض کنيد جدولي با نام sale و مطابق با چنين ساختاري داريم. اين جدول شامل اطلاعات تعداد فروش (amount) بر اساس سال (year) و به ازاي هر فصل (quarter) است.

حال مي خواهيم به عنوان مثال، اطلاعات فروش هر سال را به تفکيک هر فصل داشته باشيم.
براي اين کار از Aggregation Functionها استفاده کرده و اسکريپت زير را اجرا مي کنيم:

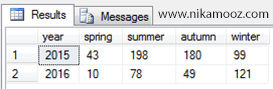
خروجي کوئري بالا، اطلاعات فروش هر سال را به تفکيک هر فصل و در قالب يک رکورد نمايش میدهد.
در ادامه اگر بخواهيم اطلاعات فروش به ازاي هر سال و بر اساس تمامي فصل¬ها صرفا در قالب يک رکورد يا يک سطر نمايش داده شود، بايد چه کار کنيم؟
با استفاده از Sub Queryها اين کار امکانپذير است!


همان طور که میبينيد، توانستيم اطلاعات فروش در هر سال و به تفکيک هر فصل را در قالب يک رکورد نمايش دهيم اما نکته قابل تامل اين است که اگر تنوع بازه زماني اطلاعات فروش بر اساس ماه هاي مختلف در نظر گرفته شده بود آن گاه میبايست تمامي ماه هاي سال را در کوئري شرکت میداديم!
اين موضوع در خصوص موجوديت هايي متنوع، قطعا چالش برانگيز خواهد بود و روش بهينه اي به حساب نمیآيد.

همان طور که میبينيد، توانستيم اطلاعات فروش در هر سال و به تفکيک هر فصل را در قالب يک رکورد نمايش دهيم اما نکته قابل تامل اين است که اگر تنوع بازه زماني اطلاعات فروش بر اساس ماه هاي مختلف در نظر گرفته شده بود آن گاه میبايست تمامي ماه هاي سال را در کوئري شرکت میداديم!
اين موضوع در خصوص موجوديت هايي متنوع، قطعا چالش برانگيز خواهد بود و روش بهينه اي به حساب نمیآيد.
اکنون براي رفع اين مشکل چه بايد کرد؟ پاسخ SQL Server استفاده از PIVOT Tableها است.
PIVOT Table چيست؟
همان طور که در شکل پایین میبينيد، خواسته ما، چرخش مقادير داده ها از درون ستون هاي جدول به سمت Header گزارش است و اين قابليت به کمک PIVOT Tableها در SQL Server تامين میشود. به عبارت ديگر زماني از PIVOT Tableها استفاده میکنيم که بخواهيم گزارش هايي از نوع Cross-Tab داشته باشيم

الگوي استفاده از PIVOT Tableها در SQL به شکل زير میباشد:

بنابراين در ابتداي کار میبايست تکليف سه مورد زير را مشخص کنيم :
1- Aggregate Column: همان فيلدي است که قرار است بر روي آن عمليات Aggregation انجام شود که در مثال فرضي ما، فيلد amount خواهد بود.
2- PIVOT Column: فيلدي که قرار است از درون رکوردها به سمت Header گزارش چرخش داشته باشد که در مثال فرضي ما، فيلد quarter خواهد بود. اين فيلد در جلو عبارت FOR قرار میگيرد.
3- ليستي که قرار است گزارش براساس آن تهيه شود که در مثال فرضي ما، مقادير فيلد quarter خواهد بود که همان spring,summer,autumn,winter خواهند بود.
اکنون با تشخيص موارد بالا، همه چيز براي ايجاد کوئري فراهم شده است:

شکل زير مقايسه ميان Plan اجرايي اين کوئري (استفاده از PIVOT) و کوئري قبلي (استفاده از Sub Query) را نشان میدهد و شما میبينيد که به لحاظ کارآيي، استفاده از PIVOT Tableها به چه ميزان تاثير گذار خواهند بود. مقايسه دياگرام Plan اجرايي اين دو کوئري هم در نوع خودش جالب توجه است. از طرفي ميزان خطوط نوشته شده در هر کوئري هم جاي تامل دارد!
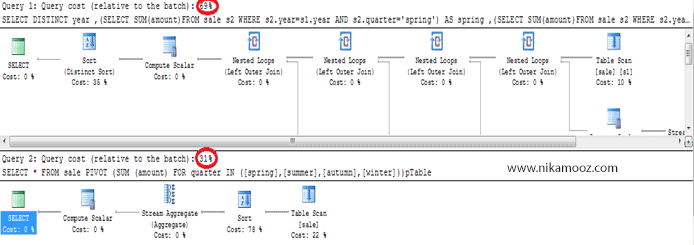
ضمنا بايد به اين نکته هم توجه داشته باشيد که با استفاده از ايندکس گذاري مناسب، قطعا میتوانيم به کارآيي بيشتر اين گونه کوئري ها کمک کنيم.
در ادمه میخواهيم تغييراتي بر روي جدول sale اعمال کنيم. اين تغييرات شامل افزودن يک فيلد از نوع INT و با خصوصيت IDENTITY است:

مجددا همان کوئري اي را که در آن از PIVOT استفاده شده بود، اجرا میکنيم.
خروجي کوئري، مطابق با آنچه که ما انتظارش را داشتيم، نيست!
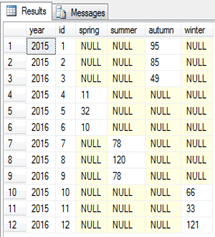
آيا میتوان چنين استنباط کرد که قابليت PIVOT صرفا براي جداول سه فيلدي ايجاد شده است؟ پاسخ مثبت و چنين برداشتي، قطعا موجب رنجش خاطر تيم توسعه دهنده Microsoft SQL Server خواهد شد!
اما بياييد با هم بررسي کنيم که چرا چنين اتفاقي افتاده و راه برون رفت از آن چيست؟
دوباره به کوئري زير توجه کنيد. فرض میکنيم هنوز به جدول مان فيلد id را اضافه نکرده ايم. کوئري زير را اجرا میکنيم:
در اين کوئري، SQL نتايج را بر اساس سال فروش (year) تفکيک کرده است. اما SQL از کجا تشخيص داده است که بايد چنين کاري را انجام بدهد؟ پاسخ آن است که در اين حالت تمامي فيلد هاي يک جدول به غير از Aggregate Column و PIVOT Column، توسط SQL در GROUP BY شرکت داده میشوند که در اين جا شامل فيلد year میشود.
منبع : نیک آموز
 مطلب قبلی
مطلب قبلی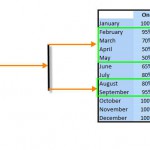 مطلب بعدی
مطلب بعدی