
آشنایی با فرایند etl
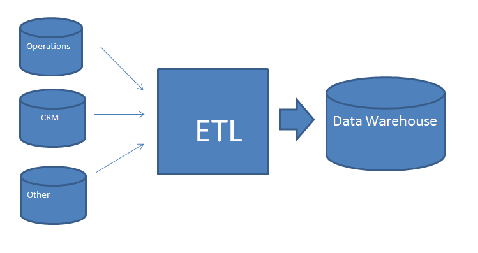
یکی از مراحل مهم پیاده سازی انبار داده برای سیستم های هوش تجاری فرآیند ETL است. امروز قصد داریم با مقاله ” همه چیز درباره ETL ” شما را بیشتر با مفهوم ETL آشنا کنیم. طی فرآیند ETL ( استخراج، تبدیل و بارگذاری ) داده ها از منابع اطلاعاتی مورد نیاز موجود در سازمان یا خارج از آن مانند، پایگاه های داده، فایل های متنی، سیستم های قدیمی و صفحات گسترده (Spread Sheets) استخراج شده و تبدیل به اطلاعاتی سازگار با سیستم جدید و با فرمت معین می شوند. سپس در یک مخزن اطلاعاتی که در اغلب اوقات یک انبار داده ( DWH ) است، قرار داده می شوند. برای انجام ETL نیاز به تخصص های مختلفی چون تجزیه و تحلیل تجاری، طراحی پایگاه داده و برنامه نویسی وجود دارد.
پیش از انجام فرآیند ETL ابتدا باید منابع اطلاعاتی که قرار است داده های آنها به انبار داده منتقل شوند، شناسایی شده و مقصد آنها در DWH مشخص شود. سپس تبدیلاتی که باید روی آنها انجام شود، تعیین شود. نحوه نگاشت اطلاعات به صورت اولیه، باید در مرحله جمع آوری نیازها و مدل سازی اطلاعات انجام شود. اطلاعات جزیی تر مربوط به نحوه نگاشت داده ها از منابع اطلاعاتی اولیه به DWH در مرحله طراحی و پیاده سازی ETL مشخص می شود.
- شناسایی منابع اطلاعاتی: پایگاه های داده mainframe مانند: VSAM ،DB2 ،IBMS Adabas و ISAM پایگاه های داده client-server مانند Informix و Oracle پایگاه های اطلاعاتی PCمانند Access، صفحات گسترده مانند Excel نمونه هایی از مهم ترین انواع منابع اطلاعاتی را تشکیل می دهند. در برخی سیستم ها شناسایی منابع اطلاعاتی به سادگی مکان یابی سرورهای پایگاه داده سیستم است. در برخی سیستم های پیچیده تر، برای شناسایی این منابع باید اعمالی نظیر تعریف دقیق فیلدهای اطلاعاتی و تعریف ارزش های اطلاعاتی مربوط به این فیلدها انجام شود.
- تعِیین مقصد داده ها: برای تمامی اطلاعات موجود در منابع اطلاعاتی شناسایی شده باید مکانی در انبار داده در نظر گرفته شود. داده های اطلاعاتی در قسمت های مختلف DWH قرار می گیرند.
- نگاشت داده های اطلاعاتی از مبدأ به مقصد: نحوه نگاشت داده ها از مبدأ به مقصد و تغییراتی که باید بر داده های اولیه اعمال شود تا به فرمت مناسب برای انبار داده درآیند باید تعیین شوند. این تغییرات موارد زیر را شامل می شود:
– خلاصه سازی اطلاعات
– تغییر اطلاعات
-کدگشایی اطلاعات کد شده
-ایجاد تغییرات لازم برای هماهنگ سازی داده های اطلاعاتی مشابه که در چند منبع اطلاعاتی مختلف وجود دارند
اطلاعات مربوط به نحوه نگاشت اطلاعات در نقشه اطلاعات (Data Map) نگهداری می شود.
یک سیستم ETL دارای چهار بخش اصلی است:
- استخراج (Extraction)
- تبدیل (Transformation)
- بارگذاری (Loading)
- Meta Data
فرایند ETL، یک پروسه محسوب می شود. به این معنی که به صورت پیوسته و مداوم در سیستم باید انجام شود. به ازای داده هایی عملیاتی که در طول زمان در سازمان به وجود می آید این فرایند نیز انجام می شود. آنچه که در استقرار هوش تجاری در سازمان مهم است ایجاد معماری و ساختاری مناسب است به طوری که در طول اجرای عملیات مختلف، ETL با سازگاری با آن فرآیند به سرعت انجام پذیرد. پس ساختار مورد استفاده برای ETL قبل از انجام آن از اهمیت بالایی برخوردار است. فرایند ETL به دلیل این که روی حجم بالایی از اطلاعات انجام می شود و معمولا همراه با یکپارچه کردن داده ها همراه است می بایست در طول دوره های مختلف انجام شود. در این دوره ها و به هنگام آغاز فرایند ETL به دلیل بالا رفتن ترافیک شبکه و پردازش سرورهای پایگاه داده ممکن است در انجام فرآیندهای دیگر تجاری BI اختلال ایجاد شود که می بایست در طراحی هوش تجاری مورد توجه قرار گیرد.
مرحله استخراج
ابتدا باید اطلاعات از منابع اطلاعاتی مورد نظر استخراج شوند. در این مرحله ممکن است اطلاعات از منبع اطلاعاتی اولیه حذف شود یا بدون حذف از آن در DWH کپی شود. اغلب داده های اطلاعاتی قدیمی که در امور روزمره سازمان کاربردی ندارند و نگهداری آنها تنها جنبه حفظ تاریخچه سیستم را دارد، از منبع اطلاعاتی اولیه حذف شده به انبار داده منتقل می شود. به این ترتیب بهره وری و کارایی منابع اطلاعاتی مذکور در سطح مطلوبی نگاه داشته می شود.
داده های استخراج شده از منابع اطلاعاتی اولیه معمولا در فضای Staging در انبار داده قرار داده می شوند و در سایر مراحل ETL مورد پردازش قرار می گیرند. این فضا معمولا یک پایگاه داده رابطه ای است که به عنوان فضای حافظه ای موقت برای پردازش اطلاعات به وجود آمده است.
مرحله استخراج اطلاعات معمولا در سطح منابع اطلاعاتی انجام می شود به ویژه اگر منبع اطلاعاتی مورد نظر، پایگاه داده باشد. در سیستم های قدیمی، روش متداول برای استخراج اطلاعات، تولید فایل های متنی از روی اطلاعات بود. در سیستم های جدیدتر از امکاناتی مانند API، OLE DB و ODBC ها برای این کار استفاده می شود.
مرحله تبدیل
پس از استخراج اطلاعات، باید پردازش هایی روی آنها انجام شود تا فرمت آنها مناسب و یکپارچه شود. در این مرحله موارد زیر انجام می شوند:
- اعتبارسنجی داده ها: سازگاری و عدم تناقض اطلاعات جدید استخراج شده از منابع اطلاعاتی و اطلاعات موجود در انبار داده در این قسمت بررسی می شود.
- بررسی صحت داده ها: آیا فیلدها مقادیر درستی به خود گرفته اند؟ برای مثال آیا در فیلدی که ارزش مقادیر on و off هستند، تمامی داده ها یکی از این دو مقدار را دارند؟
- تبدیل انواع داده ها: داده ها از منابع اطلاعاتی مختلفی می آیند و در نتیجه ممکن است فیلدهای مشابه دارای مقادیر مختلفی باشند. برای مثال یک فیلد دو مقداری در یک منبع اطلاعاتی onو off باشد و در منبع اطلاعاتی دیگر ۰ و ۱ داشته باشد. تمامی اطلاعاتی که وارد انبار داده می شوند باید از این جهت اصلاح شوند.
- اعمال قوانین تجاری: در این مرحله می توان بررسی کرد آیا داده های موجود مطابق با نیازهای سازمانی هستند؟ برای مثال آیا در اطلاعات مربوط به مشتریان نام و نام خانوادگی آنها وجود دارد.
- یکپارچه سازی اطلاعات: برای مثال ممکن است یک سیستم اطلاعات مشتریان را نگهداری کند و سیستم دیگر اطلاعات فروش را. اطلاعات موجود در دو سیستم مذکور باید با هم یکپارچه شوند.
مرحله تبدیل در واقع، پیچیده ترین مرحله در فرآیند انبار داده است. قسمتی از این فرآیند را می توان در مرحله استخراج داده ها انجام داد. مانند سیستم های اطلاعاتی قدیمی که در آنها اطلاعات از تمامی فایل های اطلاعاتی موجود جمع آوری شده و یک فایل متنی از روی آنها ساخته می شود.
مرحله بارگذاری
داده های تبدیل شده به شکل استاندارد مورد نظر، در این مرحله در پایگاه داده قرار می گیرند. داده ها معمولا به دلیل حجم بالا، به صورت دوره ای درانبار داده بارگذاری می شوند نه پیوسته. به عبارت دیگر، وقتی اطلاعات در یک منبع اطلاعاتی تغییر کرد یا اطلاعات جدیدی به آن اضافه شد، تغییرات به صورت آنی به منتقل نمی شود. بلکه به صورت دوره ای و در بازه های منظم زمانی به روز می شود.
متادیتا
Meta data اطلاعاتی در رابطه با انتقال و تبدیل دادهها، عملکرد DWH، تناظر منابع اطلاعاتی و جداول پایگاه داده ( که در آنها مشخص شده است منابع اطلاعاتی اولیه به چه قسمت هایی از DWH نگاشت شده اند) می باشد. از اطلاعات موجود در متادیتا می توان در مواردی مانند نظارت خودکار، پیش بینی گرایش های سازمان و استفاده مجدد از اطلاعات استفاده کرد. مثال هایی از meta data عبارتند از:
- اطلاعات بارگذاری داده ها: برای مثال مجموعه های داده ها در چه زمانی در DWH قرار داده شده اند.
- تغییرات schema: تغییراتی که در schema رخ میدهد. برای مثال چه تغییراتی و کی در تعاریف جداول اطلاعاتی ایجاد شده است.
- آمار تبدیلات انجام شده: اطلاعاتی مانند مدت زمان انجام تبدیل های انجام شده بر روی داده ها و تعداد رکوردهای پردازش شده در انجام این تبدیلات در این قسمت نگهداری میشوند.
برای انجام فرایند ETL می توان در سازمان برنامه های نرم افزاری مورد نیاز را نوشت. این برنامه ها عموما برنامه های پیچیده ای هستند. از این رو ابزارهای زیادی برای ETL به وجود آمده اند به طوری که می توان از آنها برای این منظور استفاده کرد. یک ابزار ETL خوب باید بتواند با پایگاه های داده مختلف ارتباط برقرار کند و فایل هایی با فرمت های مختلف که در سازمان های مختلف متفاوت است را بخواند.
 مطلب قبلی
مطلب قبلی مطلب بعدی
مطلب بعدی