
مراحل داده کاوی

:
- 1- مرحله اول : تشکیل انبار داده
- 2- مر حله دوم : انتخاب داده ها
- 3- مرحله سوم : تبدیل داده ها
- 4- مرحله چهارم : کاوش در داده ها
- 5- مر حله پنجم : تفسیر نتیجه
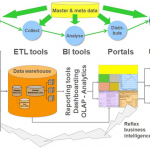
1- انباره داده ها (Datawarehouse)
در اين نوشته، نگاهي خواهم داشت به مقدمات مفاهيم انبارکردن داده ها بدون ورود به بحث هاي تخصصي مرتبط تا در آينده بتوانم در مطلب مستقلي به مفهوم داده در سازمانهاي امروزي نگاهي داشته باشم.
تعريف: مي توان تعاريف مختلفي را براي Datawarehouse:
1- تعريف Ralhp Kimball از انباره داده : يک DW نسخه اي از داده هاي تراکنشي است که به صورت اختصاصي براي پرس و جو ها و گزارش گيري ،سازمان دهي شده است.
A data warehouse is a copy of transaction data specifically structured for querying and reporting.
گرچند به اين تعريف دو ايراد وارد است:که اولاً گاهي داده هايي که در يک DW ذخيره مي شوند ،غيرتراکنشي هستند . اگرچه معمولاً 95 تا 99 درصد داده ها تراکنشي هستند . ثانياً خروجي اصلي سيستم هاي DW ، ليست گيري هاي فهرست وار (queries) در حجم کم و يا گزارش هاي اداري در حجم زياد هستند
2- اگر تعاريف زير برقرار باشد:
داده : حقحيقت قابل مشاهده ، فايل ضبط
اطلاع : مجموعه سازماندهي شده از حقيقت ها ؛ داده هاي با ارتباط و هدف
سيستم عملياتي : محيطي از داده ها و برنامه هاي لازم براي ادامه فعاليتهاي يک سازمان
انبار داده ي اطلاعي :مجموعه اي از داده و برنامه ها، براي “تحليل ” و “تصميم گيري “، جدا از سيستم عملياتي
يک انباره داده(DW) معماري جداگانه اي است براي نگهداري داه هاي حساس تاريخي که اين داده ها از انبار داده هاي عملياتي به دست آمده اند و به صورتي قابل درک براي عمليات تحليل سازمان درآمده اند.
3- يک تعريف از W.H.INMON
يک DW مجموعه اي از اطلاعات يکپارچه که داراي قابليت آناليز کردن و استخراج داده ها (query)ميباشد
“repository of integrated information, available for querying and analysis ”
بعضي از خصوصيات Data warehouse ها از اين قرارند :
•يکپارچه بودن
•متغير با زمان
•غير فرار
•موضوع گرا (Subject-oriented)
تاريخچه:
بعد از رشد استفاده از TPS ها به عنوان سيستمهاي پرداش تراکنش در بخش هاي عملياتي سازمان، نياز جدي به سيستمهاي اطلاعاتي که بتوانند عمليات گزارش گيري را علي الخصوص در رده گزارشهاي مديريتي ساماندهي کنند احساس مي شد. علي الخصوص بوجود آمدن جزاير فنآوري، سيستمهايي که به صورت جد از هم فعاليت مي کرد و امکان تهيه گزارشات ترکيبي از اطلاعات سيستمهاي مختلف و انجام پرس و جو ها را مشکل و يا غير ممکن مي نمود. بنابراين حرکت به سمت سيستمهاي اطلاعات مديريت (Management Information System) و بويژه سيستمهاي گزارشگيري مديريتي (MRS:Management Reporting System) آغاز شد. اما مشکل آنجا بود که اين سيستمها به شدت به TPS ها وابسته بودند و داده هاشان اغلب يکي بود. اين باعث مي شد که تغيير يکي باعث انتشار تغييرات در همه سيستمها شود. از سوي ديگر ساختار داده اي مشابه، امکان تهيه گزارشات زماني و موضوعي را مشکل مي ساخت. اين شد که مدل جديدي از تفکر ايجاد شد به نام انباره داده ها
دلايل استفاده از DW ها :
1- تهيه گزارشات (Reports) و انجام پرس و جو هايي (Query) که نياز به عمليات ورودي/خروجي (IO) بسياري هستند: از اهداف سيستمهاي پردازش تراکنش (TPS:Transaction Processing System) آن است که گزارشات مورد نياز بخش هاي عملياتي و مديريتي را توليد کنند. تهيه اين گزارشات معمولا سخت و باحجم زياد IO همراه است و باعث کند شدن خود سيستمها مي گردد. بنابراين شرکت هاي تجاري به دنبال راهي هستند تا در کمترين زمان و با کمترين هزينه به سيستم هايي دست يابند که زمان پردازش تراکنش ها در آن ها قابل قبول باشد . بهترين راهکار استفاده از DW هايي بود که از منابع IO مجزايي براي گزارش گيري و انجام پرس و جو استفاده مي کردند.
2- استفاده از مدل هاي داده اي و يا تکنولوژي هاي سرور به منظور بالا بردن سرعت عمليات گزارش گيري و پرس و جو ها که سيستم هاي عادي پردازش تراکنش ها(TPS) براي آن ها مناسب نيست.
3- ايجاد محيطي براي براي تسهيل و آسان نمودن به دست آوردن گزارش ها و پرس و جو ها و يا ايجاد وسيله اي براي سرعت بخشيدن به عمليات گزارش گيري: اغلب مي توان DW اي ساخت که کاربراني باسطح آگاهي کمتر بتوانند گزارش ها و پرس و جوهاي ساده اي را تهيه کنند .
4- براي ايجاد انباري از داده هاي تصفيه شده ي سيستم هاي پردازش تراکنش ها (TPS)که مي توانند به طور پيوسته گزارش از آن تهيه نمود. اين انبار الزاماً احتياجي به ثابت بودت TPS ها ندارد :DW ها اين امکان را به شما مي دهند که داده ها را بدون تغيير دادن سيستم هاي پردازش تراکنش ها ،تصفيه کنند. (clean up) توجه کنيد که در برخي از پياده سازي ها ، DW ها به گونه اي هستند که در آن ها امکان يافتن اصلاحات انجام شده بر روي داده هاي DW و فرستادن feedback به TPS ها براي اعلام اين تغييرات ، وجود دارد. گاهي اوقات اين گونه رفتار کردن با تغييرات داده ها بامعناتر از اين است که تغييرات را به طور مستقيم بر روي خود TPS ها اعمال کنيم .
5- براي آن که بر اساس قواعد ، گزارش گيري و پژوهش را بر روي داده هايي که از چندين TPS مختلف مي آيند و يا از يک منبع داده اي خارجي مي آيند، يا اينکه داده هايي هستند که تنها براي گزارش گيري و انجام تحقيقات بايد ذخيره شوند ، تسهيل بخشيم:براي مدت زمان مديدي ، شرکت هايي که نياز به گزارش هايي بر پايه ي داده هاي چندين TPS مختلف ، داشتند ؛ مجبور بودند داده هاي هر TPS را بيرون کشيده ، سپس آن ها را مرتب نموده و در هم ادغام نمايند تا به داده ي چکيده اي برسند که مناسب گزارش گيري است .در بسياري از موارد اين روش مناسب است.اما در شرکت هايي که با حجم عظيمي از داده هايي مواجه هستند که مرتباً نياز به مرتب سازي و ادغام دارند ؛ در صورتي که نياز به گزارش گيري از داده هاي تصفيه شده ي TPS ها داشته باشيم ؛ DW ها کارايي بيشتري دارند.
6-براي ايجاد مخزني از داده هاي TPS ها ، که شامل داده هاي يک بازه ي زماني بسيار طولاني هستند وبه همين دليل کارايي کنترل آن ها توسط خود TPS پايين مي آيد . :داده هاي قديمي تر غالباً از يک TPS خالي مي شوند تا زمان پاسخ مورد انتظار دراين سيستم ها ، به راحتي کنترل شود .براي انجام تحقيقات و گزارش ها ممکن است داده هاي قديمي و داده هاي جاري مورد نياز باشند که در اين موارد استفاده از DW به علت مهم نبودن زمان انتظار براي پاسخ ، موثر خواهد بود.
روش کار
در DW فرايندي داريم به نام ETL: Extract, Transform,Load که در طي آن داده ها از سيستمهاي پرادزش تراکنش استخراج مي شود (E) تغيير فرمت هاي لازم در آن صورت مي گيرد (T) و سپس در قالب داده اي جديد مناسب براي گزارشگيري آماده مي شود (L) پس از آن از طريق داده کاوي (Data Mining ) و مکانيزم هايي مانند OLAP پرس و جو ها ايجاد و گزارشات مورد نياز تهيه مي شود.
2- مر حله دوم : انتخاب داده ها
در این مرحله برای کم کردن هزینه های عملیات داده کاوی، داده هایی از پایگاه داده انتخاب می شوند که مورد مطالعه هستند و هدف داده کاوی دادن نتایجی در مورد آنهاست. به عبارت دیگر داده های مرتبط به فرايند Data Mining از ساير داده ها جدا می شود. اين مبحث را می توان بخشی از فرايند کاهش اطلاعات نيز دانست.
کاهش اطلاعات عبارت است از توليد يک مجموعه کوچکتر از داده های اوليه که تحت عمليات Data Mining نتايج تقريبا يکسانی با نتايج Data Mining روی اطلاعات اوليه به دست می دهد.
اين عمل را می توان از طريق حذف خصيصه های غير مرتبط با نوع عمليات Data Mining مورد نظر انجام داد.
حذف خصيصه های مرتبط که در اثر اشتباه در ارزيابی ميزان ارتباط آنها با عمليات Data Mining انجام می گيرد، می تواند منجر به ناکارآمدی فرايند Data Mining و استخراج قوانين ناقص و در نتيجه بی ارزش شود.
عدم حذف خصايص غير مرتبط می تواند زمان انجاخم عمليات Data Mining را به طرز قابل ملاحظه ای افزايش دهد.
سه روش کلی برای انتخاب خصايص مرتبط با Data Mining وجود دارد:
• انتخاب پيش رونده: در هر مرحله خصيصه ای که بيشترين ارتباط را دارد، برگزيده می شود.
• انتخاب عقب رونده: در هر مرحله خصيصه ای که کمترين ارتباط را دارد، انتخاب و حذف می شود.
• روش ترکيبی : ترکيب هر دو روش پيش رونده و پس رونده
سلسله مراتب مفهومی: روشی برای کاهش تعداد مقادير ممکن برای يک خصيصه ارائه می دهد، اگر چه داده های خروجی کلی تر بوده و فاقد برخی جزئيات هستند، اما اين داده ها بسيار ساده تر بوده و در سطح تجريدی بالاتری نسبت به داده های اوليه قرار دارند.
داده های مرتبط با فرايند Data Mining: بانک اطلاعاتی ممکن است شامل تعداد زيادی از رکورد ها باشد که تنها بخش کوچکی از آنها با فرايند Data Mining مرتبط هستند. مشخص کردن اين بخش از اطلاعات بايد توسط کاربر انجام گيرد.
نوع دانشی که بايد استخراج شود: نوع روتين هايی که بايد بر روی داده های انتخاب شده اعمال شوند، بايد مشخص گردد.
دانش زمينه ای : کاربران می توانند، با مشخص کردن دانش زمينه ای فرايند Data Mining را هدايت نمايند، برای نمونه حدس کاربر در مورد رفتار اطلاعات.
معيارهای ارزيابی دانش استخراج شده: اين معيارها ممکن است در زمان اجرای فرايند Data Mining و يا پس از پايان Data Mining ، روی دانش استخراج شده اعمال شده و بخش ارزشمند دانش را مشخص نمايند.
نحوه ارائه دانش استخراج شده: نمايش دانش و قوانين استخراج شده در قالب های مختلفی نظير جدول ، نمودار ، درخت تصميم گيری و …
3- مرحله سوم: تبدیل داده ها
از آنجائیکه سیستمهای اطلاعاتی و برنامه های کاربردی یک سازمان غالبا توسط افراد و پروژه های مختلف به مـرور زمان در مواجهـه با نیـازهای جدید سـاخته یا تغییر شـکل داده می شـوند، یکسـان سـازی آنها امری ضروری می باشد.در بسیاری از موارد نیز سیستمهای اطلاعاتی در بستر های مختلف پایگاه داده مانند Microsoft SQL Server ،Oracle ، Sybase ، Microsoft Access و غیره طراحی گردیده اند. بررسی جداول، برقراری ارتباط بین فیلدها و یک شکل سازی داده ها در این مرحله صورت می پذیرد.
مشخص است برای انجام عملیات داده کاوی لزوما باید تبدیلات خاصی روی داده ها انجام گیرد ممکن است این تبدیلات خیلی راحت و مختصر مثل تبدیل byte به integer باشد یا خیلی پیچیده و زمان بر و با هزینه های بالا مثل تعریف صفات جدید و یا تبدیل و استخراج داده ها از مقادیر رشته ای و … باشد.
كيفيت اطلاعات براي انتخاب و استفاده از اطلاعات موجود و عرضه شده در سازمان يا خارج از آن ، از اهميت فراواني برخوردار است. از سويي ديگر نياز به اطلاعات گوناگون براي بقاء هر سازمان با توجه به افزايش پيچيدگي، پويايي و تغييرات محيطي در حال فزوني است. اين امر با توجه به رشد نمايي اطلاعات و از طرفي ديگر كوتاه بودن اعتبار آن ابزار و روشهاي مناسبي را طلب مي نمايد تا توسط آن به كيفيت اطلاعات اطمينان پيدا نمود. از اينرو با توجه به اهميت كيفيت اطلاعات، ارزيابي كيفيت اطلاعات براي دستيابي به اطلاعات موردنياز سازمان امري مهم و ضروريست و لازم است تا با ايجاد ابزار مناسب (ساختار، ابزار، انسان و …) اين مهم را به صورت صحيح و مؤثر مديريت نمود. از آنجا كه موضوع كيفيت ابعاد متفاوتي دارد لذا در ادامه بحث به معرفي كلي اين ابعاد از منظر مديريت كيفيت پرداخته مي شود؛ تا با كسب اين آشنايي اجمالي، بتوانيم ضمن شناخت محورهايي كه مي بايست در مورد آنها اطلاعات كسب شود، ابعاد كيفيت اطلاعات مربوط به اين عوامل نيز بازيابي و شناسايي گردند. ابعاد كلي مختلفي كه در ايجاد كيفيت، نقش ايفاء مي نمايند در جدول شماره يك درج شده اند. با توجه به اين ابعاد مي توان ضمن شناخت اطلا عا ت مورد نياز منابع توليد اين اطلاعات را نيز شناخت.
كيفيت اطلاعات به خودي خود قابل رويت نيست، بلكه كيفيت آنرا مي توان از صحت آن و نتايج آن سنجيد. صحت اطلاعات نيز در مرحله اول قابل رويت نيست بلكه آنرا با ارزيابي ارائه كننده و درجه اطمينان آنان مي توان وابسته نمود. از سوي ديگر اطلاعات معمولاً وابسته به زمان است يعني آنكه اعتبار آن ممكن است كه در طول زمان از بين برود. به عنوان مثال (ليست قيمت يك كالا، دقت يك دستگاه وميزان تقاضا در بازارو. …) از اينرو بايد به صورت مستمر با ايجاد / تعيين مقياس و شاخص هاي مناسب براي اطلاعات مورد نياز، كيفيت اطلاعات را به صورت پويا و مستمرمورد بررسي قرار داد. كيفيت اطلاعات يك مجموعه از نيازهاي اطلاعاتي است كه براي برطرف نمودن يك نياز اطلاعاتي/ انجام كاري در سازمان مورد نياز است (فرآيند – مشتري – ساختار – كاركنان – محصول – خدمات و …) تا با استفاده از آنها، كارها درست و بصورت اثر بخش انجام گردند. در اين راستا مرتبط بودن – واضح بودن – معتبر بودن – به موقع بودن – قابل دستيابي بودن و … از جمله مواردي است كه اطلاعات با كيفيت مطلوب مي بايست دارا باشد.
4- مرحله چهارم : کاوش در داده ها
کاوش داده اغلب با نوشتن مقدار زیادی گزارش و تحقیق و استعلام از آنها اشتباه میشود. اما در واقع کاوش داده هیچکدام از اینها را شامل نمی شود. کاوش داده از طریق تجهیزات مخصوصی انجام میشود که عملیات کاوش از پیش تعریف شده را بر اساس مدلهای تجزیه و تحلیل انجام میدهند. کاوش داده، بررسی داده ها با تمایل به کشف نکات با ارزش و مفید اطلاعات در مقدار متنابهی از داده ها که در طول کار و تجارت بدست آمده است می باشد. کاوش داده با آنالیزهای متداول آماری نیز متفاوت است. در زیر تفاوتهای کاوش داده و آنالیز آماری آمده است. انبار داده Data warehouse از جمله منابع معمول برای بکارگیری کاوش داده هستند زیرا شامل منابع با ارزشی از داده های داخلی که بوسیله روشهای استخراج/ انتقال/ بارگزاری (ETL) جمع آوری، یکپارچه و تایید شده اند.
انبار داده ها همچنین میتوانند شامل داده های با ارزش خارجی مانند قوانین و ضوابط، جمعیت شناسی یا داده های جغرافیایی باشند که وقتی با داده های داخل سازمانی مخلوط میشوند اساس کاوش داده را پی ریزی میکنند. اما وقتی داده برای انبار داده خلاصه شد، داده های مخفی و روابط و پیوستگی داده ها دیگر قابل تمییز نمی باشند. برای مثال یک ابزار نمیتواند دیگر به بررسی معمولی که بر روی سبد خرید مشتریها با داده های فروش که در هفته خلاصه شده بپردازد زیرا در خلاصه شدن جزییات و روابط و پیوستگیها از بین رفته است. به همین دلیل فایلها و بانکهای داده عملیاتی نیز بعنوان یک منبع معمول هستند زیرا شامل جزییات مبادلاتی و هزاران داده های مخفی هستند.
ابزارهای کاوش داده با بانکهای داده عملیاتی و انبار داده ها بطور مستقیم بدون ساخت بانک داده دست پیدا میکنند. اما بعضی از ابزارهای کاوش داده مثلا روابطی مانند Oracle ، طبقه بندی مانند IMS و حتی فایلهای مسطح مانند VSAM ترجیح میدهند خود نیز یک بانک داده داشته باشند. اما دسترسی مستقیم به انبار داده ها و داده های عملیاتی اصولا توصیه نمی شود .
زیرا:
- حوضچه های داده Data Pool باید قادر باشند بسته به ابزار کاوش داده تغییر کنند اما تعویض جزئیات یک داده عملیاتی و یا بانکهای اطلاعاتی انبار داده ممکن نمیباشد.
- عملکرد داده های عملیاتی و یا بانک داده با عملیاتهای جستجوی داده تحت تاثیر قرار میگیرند. این برای داده های عملیاتی غیر قابل قبول و برای انبار داده ها مطلوب نیست.
- یک عملیات کاوش داده ممکن است به جزئیات تاریخی داده احتیاج داشته باشد. بانکهای اطلاعاتی عملیاتی جزئیات تاریخی را نگه نمی دارند و انبار داده ها جزئیات مطلوب را ندارد. بنابر این همانطور که در شکل صفحه قبل آمده است، سازمانها داده ها را برای کاوش داده با توجه به هدف کاوش از انبار داده و یا بانک داده عملیاتی استخراج می کنند.
 مطلب بعدی
مطلب بعدی